How Google Detects Signal Exploitation From Consistent Ranking Patterns
Posted On : February 27th, 2026 By : Diptimayee Mohanty To : Google, Google PatentsWhat Is Signal Exploitation
Search engine ranks web pages, PDFs or videos based on many different ranking signals, such as quality, relevance, and user clicks, etc. Signal exploitation happens when someone figures out exactly which “ranking signal” the search algorithm cares about and artificially inflates it to jump to the top of the results.
- Example: Imagine a restaurant that buys hundreds of fake 5 or 4-star reviews to show up first in “Best Restaurants in Los Angeles” searches, even though their food is actually terrible. They are “exploiting” the review signal to get a top ranking.
The Core Problem for Google: Is it Relevant, or is it an Exploit?
When Google ranks a web page, its algorithm evaluates various “ranking signals” (also known as ranking factors), such as keyword density, content freshness, links, and formatting, etc.
A major technical challenge for Google is that resource publishers (like website owners or SEOs) can manipulate or “exploit” these individual signals to artificially boost their page rankings for specific queries. When Google’s system sees an abnormally high score for a specific ranking signal, it faces a dilemma: is this content just exceptionally relevant, or is the creator successfully exploiting the search system?
Google filed a patent in mid 2024 that was published recently, titled “Detecting signal exploitation from consistent ranking patterns” Patent No: US20260023790A1 . It’s about how Google fights spam or over-optimisation, whether on-page or off-page, tackling it algorithmically rather than manually. This patent describes a way to catch and demote “bad actors” who try to manipulate search engine rankings or recommendation systems. In short, it’s a high-tech way of spotting someone who is “gaming the system.”
How the Detection Algorithm Works
To address this, Google’s patent describes a statistical method for distinguishing between manipulated and naturally relevant ranking signals. Instead of checking only a single page, it looks for patterns across the whole website.
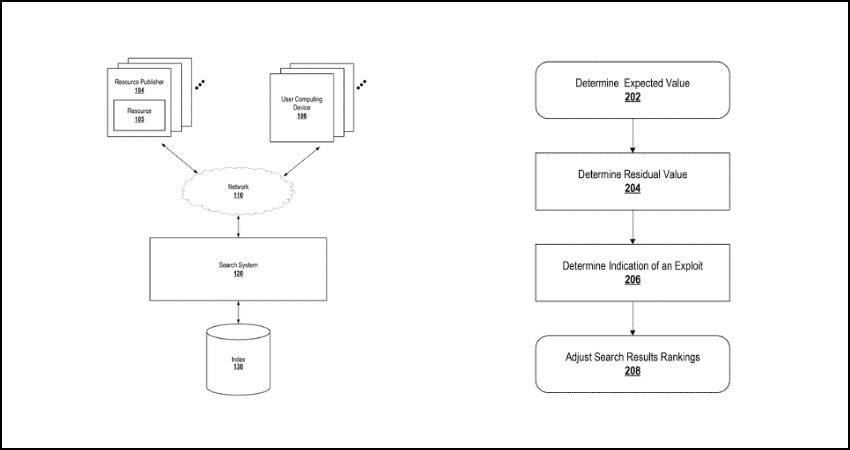
Here is the step-by-step breakdown of the process:
- Step 1: Determine the “Expected Value”: First, Google looks at a group of resources (web pages) that are responsive to a specific query. It aggregates their scores to determine an “expected value” for a given ranking signal. This is often calculated using a linear regression model of the aggregate scores.
- Step 2: Calculate the Difference (Z-Score): The system then measures the difference (or “Z-score”) between a specific page’s actual signal score and the calculated expected value.
- Step 3: Aggregate at the Domain Level: This is the crucial step. Google aggregates these Z-score differences across multiple pages within the same domain. This creates a “residual value” for the domain as a whole.
- Step 4: Identify the Exploit: For a normal, non-manipulative domain, the positive and negative differences across its pages will naturally cancel each other out, resulting in a small average residual value. However, if a domain systematically exploits a ranking signal, it will have consistently high, positive values, resulting in a large average residual. A large residual value is a clear indicator of signal exploitation.
- Exceptions: The system explicitly excludes “navigational queries” (e.g., a user searching for a specific website, such as “Facebook login”). This is because the ranking signals for navigational results are naturally skewed and do not reliably indicate abuse.
A Simple Example
Adding a simple example first will help to understand the core concept of this patent. To see how this works in practice, imagine a ranking signal based on keyword density.
- The Baseline: For a query about “best hotel in Dallas” Google’s linear regression model determines that the expected keyword density score for a top-ranking page should be 1.5.
- The Suspect Domain: “Domain X” decides to aggressively keyword-stuff its pages to manipulate this signal. Its page scores a 3.5 for keyword density.
- Calculating the Z-Score: Google calculates the difference for that page: 3.5 (Actual) – 1.5 (Expected) = +2.0
- Catching the Exploit: Google doesn’t just look at that one page; it looks at the residual average across the Domain X. Let’s say it finds differences of +2.0, +1.8, +2.2, and +1.9 across various pages on Domain X. Because these numbers don’t cancel out and the average residual remains very high, Domain X is officially flagged as exploiting the ranking system.
The Baseline Formula
The patent describes building a linear regression model using the classic straight-line formula:
y = a*x + b
Here is how Google defines those variables in the context of their search algorithm:
- The X-Axis (x): This represents the overall information retrieval score (the final ranking score for the page). It is calculated using a function of all the different ranking signals combined, represented in the patent as f(A,B,C,D). A,B,C & D are various ranking signals like keyword density or review score, etc.
- The Expected Value (y): This is the baseline expected score for one specific ranking signal being evaluated (for example, signal A).
- The Slope (a) and Bias (b): The system determines (or “learns”) the slope and the bias by analysing data included in historical search records.
To build this model, the search system plots a series of data points and fits a line—a straight line of “best fit”—from the log of the overall information retrieval score to the Z-score of the log of the specific ranking signal.
Calculating the Exploit (The Residual)
Once that line of best fit establishes the expected baseline—which is (a*f(A,B,C,D) + b)—the system calculates the residual value r (the exact amount of deviation) for a specific document using this formula:
r = A – (a*f(A,B,C,D) + b)
In this formula, A is the actual score the page received for that specific ranking signal.

- If A is massively higher than the expected baseline (a*f(A,B,C,D) + b), the resulting residual r will be a large positive number. If a whole domain consistently outputs large positive residuals, it gets flagged for an exploit.
Example Of Google SERP Scenario
Imagine a user searches for the query “Best Restaurants in Los Angeles“.
Google’s algorithm is evaluating the top 10 pages using multiple ranking signals. For this example, we will focus on just one signal: Keyword Density (let’s call it “Signal A”).
- Overall Score x: This is the page’s total ranking score, combining all signals.
- Actual Signal A: This is the score the page received specifically for its Keyword Density.
Here are our example of top 10 results before the patent’s detection algorithm kicks in:
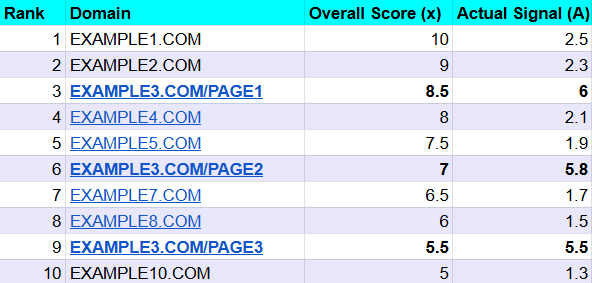
You can see that EXAMPLE3.COM has three pages ranking in the top 10, and their Signal A scores are suspiciously high compared to the others.
Step 1: Calculate the “Expected Value”
Google’s system assumes that legitimately highly-ranked pages should naturally have higher scores across all ranking signals. To find out exactly what score a page should have for Signal A, Google builds a linear regression model based on historical data.
The system uses a straight-line formula, y=a*x+b, where the slope (a) is strictly constrained to a non-negative value.
Let’s assume the learned formula for “Best Restaurants in Los Angeles” is Expected Value = 0.2 * x + 0.5
Step 2: Calculate the Residuals (The Differences)
Now, the system calculates the “residual” (the difference) for every single page by subtracting the Expected Value from the Actual Signal A score.
Let’s look at a normal site versus our spammy site:
- EXAMPLE1.COM (Rank 1):
Expected Value = 0.2 * 10.0 + 0.5 = 2.5
Residual Value= 2.5 – 2.5 =0.0 (Exactly on trend)
- EXAMPLE3.COM/PAGE1 (Rank 3):
Expected Value = 0.2 * 8.5 + 0.5 = 2.2
Residual Value= 6.0 – 2.2 = +3.8 (Massive deviation)
Step 3: Aggregate at the Domain Level
This is where Google catches the exploit. Instead of just penalising one page, the system groups all these residuals by their root domain.
- For a normal, healthy domain, some pages might be slightly above or slightly below the expected trend. These positive and negative numbers cancel each other out, leaving a very small average residual.
- However, if a domain systematically exploits a signal, it will show consistently high positive values.
When Google averages the residuals for EXAMPLE3.COM, it sees +3.8, +3.9, and +3.9 across its pages. Because this domain’s average is exceptionally large, the system officially flags the entire domain as an “outlier” that is abusing the ranking signal.
How Google Uses This to Rank Web Pages
When a domain crosses a threshold and is flagged for exploiting the ranking system for a specific signal, Google initiates a targeted demotion.
- Bringing it “Back to Trend”: Instead of outright banning the website, Google may adjust the ranking by bringing the exploited signal back to its expected trend.
- Assigning the Expected Value: It may literally strip the manipulated score (the 6.0) away and formally assign the mathematically Expected Value (the 2.2) to that page’s information retrieval score.
Because EXAMPLE3.COM’s overall score was artificially inflated by that 6.0, resetting it to 2.2 causes its overall ranking score to plummet. By doing this, Google can completely neutralise the unfair advantage of the exploit. The demoted resources fall to their rightful place in the search results, ensuring users see genuinely relevant content rather than manipulated spam.
What Website Owners Should Do To Avoid The Ranking Drop
Based strictly on the concept outlined in this Google patent, the key to avoiding or recovering from this specific demotion is to break the mathematical patterns that make your site look like an “outlier domain”
Here is exactly what website owners should do based on the algorithm’s logic:
1. Avoid Sitewide “Over-Optimisation”
The most critical takeaway from this patent is that Google isn’t just looking at one over-optimised page; it is looking for an exploit across a domain
- The Trap: If a website owner finds an SEO trick (like a specific keyword density, exact heading structure, or specific metadata pattern) and aggressively applies it to every single page on their site, they are creating a massive, red-flag data trail.
- The Fix: Stop applying rigid, formulaic SEO templates to every page. The patent states that an exploiting domain is caught because it has “consistently high (positive) values for the signal and therefore has a large average residual”. If you vary your approach, your domain average won’t trigger the alarm.
2. Embrace Natural Variation
The algorithm explicitly expects normal, non-spammy websites to have a mix of high and low scores for any given ranking signal.
- The Math Behind It: The patent explicitly notes that for a normal domain, “the residual average should be small because the positive and negative values in these measured differences cancel each other out”.
- The Fix: Allow your pages to be natural. Some pages might naturally have a high keyword density because of the topic, while others might have a very low one. Let those negative and positive Z-scores balance each other out across your domain.
3. Focus on Overall Relevance, Not Single Signals
The system calculates the “expected value” of a signal based on how well the page’s overall profile matches what is predicted for a highly relevant result.
- The Trap: The patent mentions that the signals being evaluated are derived from content that is “configurable by the respective resource publishers”. If you try to artificially inflate a configurable signal (like stuffing keywords) without actually improving the overall quality and relevance of the page, your actual score will massively exceed the expected score.
- The Fix: Build content that matches the “expected (e.g., typical) values” for your topic. If your page is genuinely helpful and relevant, its natural signals will align with Google’s expected linear regression models, keeping you off the outlier list.
How to Recover if Hit
If a site is already penalised by this system, the patent reveals exactly how the punishment works: the site’s manipulated signal is simply “brought back to trend” (assigned the expected value). To recover, the publisher must audit their site, identify which “configurable” content element they have been artificially inflating across their domain, and scale it back to normal, natural levels so their aggregated domain score drops below the penalty threshold.

- How Google Detects Signal Exploitation From Consistent Ranking Patterns - February 27, 2026
- SEO Best Practices Post-Google Search Update March 2024 - October 9, 2024
- Do SEOs Need To Know HTML? - December 20, 2021