WebGPT: Improving the Factual Accuracy of Language Models through Web Browsing
March 23, 2022
We’ve fine-tuned GPT-3 to more accurately answer open-ended questions using a text-based web browser. Our prototype copies how humans research answers to questions online—it submits search queries, follows links, and scrolls up and down web pages. It is trained to cite its sources, which makes it easier to give feedback to improve factual accuracy. We’re excited about developing more truthful AI,1 but challenges remain, such as coping with unfamiliar types of questions.
Language models like GPT-3 are useful for many different tasks, but have a tendency to “hallucinate” information when performing tasks requiring obscure real-world knowledge.23 To address this, we taught GPT-3 to use a text-based web-browser. The model is provided with an open-ended question and a summary of the browser state, and must issue commands such as “Search …”, “Find in page: …” or “Quote: …”. In this way, the model collects passages from web pages, and then uses these to compose an answer.
The model is fine-tuned from GPT-3 using the same general methods we’ve used previously. We begin by training the model to copy human demonstrations, which gives it the ability to use the text-based browser to answer questions. Then we improve the helpfulness and accuracy of the model’s answers, by training a reward model to predict human preferences, and optimizing against it using either reinforcement learning or rejection sampling.
How do neural networks work?
ELI5 results
Our system is trained to answer questions from ELI5,4 a dataset of open-ended questions scraped from the “Explain Like I’m Five” subreddit. We trained three different models, corresponding to three different inference-time compute budgets. Our best-performing model produces answers that are preferred 56% of the time to answers written by our human demonstrators, with a similar level of factual accuracy. Even though these were the same kind of demonstrations used to train the model, we were able to outperform them by using human feedback to improve the model’s answers.
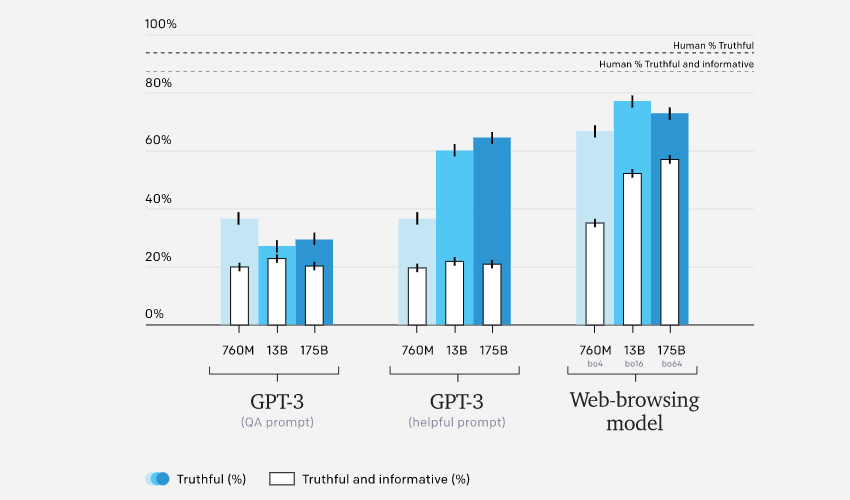
TruthfulQA results
For questions taken from the training distribution, our best model’s answers are about as factually accurate as those written by our human demonstrators, on average. However, out-of-distribution robustness is a challenge. To probe this, we evaluated our models on TruthfulQA,5 an adversarially-constructed dataset of short-form questions designed to test whether models fall prey to things like common misconceptions. Answers are scored on both truthfulness and informativeness, which trade off against one another (for example, “I have no comment” is considered truthful but not informative).
Our models outperform GPT-3 on TruthfulQA and exhibit more favourable scaling properties. However, our models lag behind human performance, partly because they sometimes quote from unreliable sources (as shown in the question about ghosts above). We hope to reduce the frequency of these failures using techniques like adversarial training.