
AI Safety Needs Social Scientists
March 23, 2022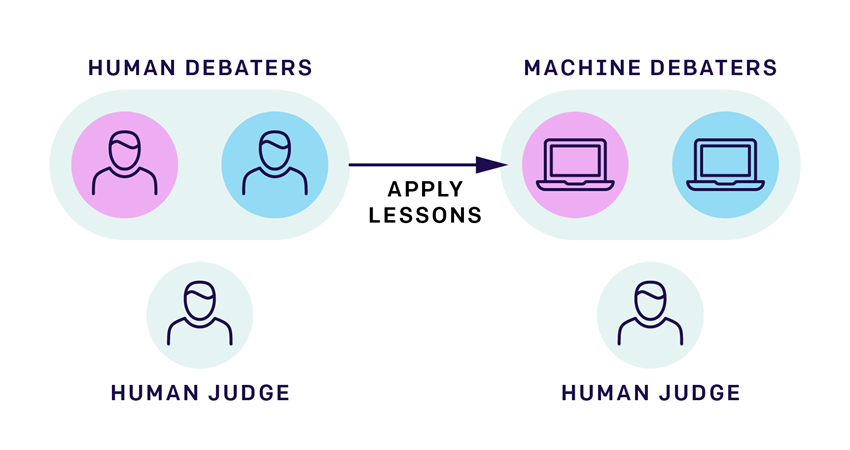
The goal of long-term artificial intelligence (AI) safety is to ensure that advanced AI systems are aligned with human values — that they reliably do things that people want them to do. At OpenAI we hope to achieve this by asking people questions about what they want, training machine learning (ML) models on this data, and optimizing AI systems to do well according to these learned models. Examples of this research include Learning from Human Preferences, AI Safety via Debate, and Learning Complex Goals with Iterated Amplification.
Unfortunately, human answers to questions about their values may be unreliable. Humans have limited knowledge and reasoning ability, and exhibit a variety of cognitive biases and ethical beliefs that turn out to be inconsistent on reflection. We anticipate that different ways of asking questions will interact with human biases in different ways, producing higher or lower quality answers. For example, judgments about how wrong an action is can vary depending on whether the word “morally” appears in the question, and people can make inconsistent choices between gambles if the task they are presented with is complex.
We have several methods that try to target the reasoning behind human values, including amplification and debate, but do not know how they behave with real people in realistic situations. If a problem with an alignment algorithm appears only in natural language discussion of a complex value-laden question, current ML may be too weak to uncover the issue.
To avoid the limitations of ML, we propose experiments that consist entirely of people, replacing ML agents with people playing the role of those agents. For example, the debate approach to AI alignment involves a game with two AI debaters and a human judge; we can instead use two human debaters and a human judge. Humans can debate whatever questions we like, and lessons learned in the human case can be transferred to ML.
These human-only experiments will be motivated by machine learning algorithms but will not involve any ML systems or require an ML background. They will require careful experimental design to build constructively on existing knowledge about how humans think. Most AI safety researchers are focused on machine learning, which we do not believe is sufficient background to carry out these experiments.
To fill the gap, we need social scientists with experience in human cognition, behavior, and ethics, and in the careful design of rigorous experiments. Since the questions we need to answer are interdisciplinary and somewhat unusual relative to existing research, we believe many fields of social science are applicable, including experimental psychology, cognitive science, economics, political science, and social psychology, as well as adjacent fields like neuroscience and law.
We believe close collaborations between social scientists and machine learning researchers will be necessary to improve our understanding of the human side of AI alignment. As a first step, several OpenAI researchers helped organize a workshop at Stanford University’s Center for Advanced Study in the Behavioral Sciences (CASBS) led by Mariano-Florentino Cuéllar, Margaret Levi, and Federica Carugati, and we continue to meet regularly to discuss issues around social science and AI alignment. We thank them for their valuable insights and participation in these conversations.








