Lessons Learned on Language Model Safety and Misuse
March 23, 2022
The deployment of powerful AI systems has enriched our understanding of safety and misuse far more than would have been possible through research alone. Notably:
- API-based language model misuse often comes in different forms than we feared most.
- We have identified limitations in existing language model evaluations that we are addressing with novel benchmarks and classifiers.
- Basic safety research offers significant benefits for the commercial utility of AI systems.
Here, we describe our latest thinking in the hope of helping other AI developers address safety and misuse of deployed models.
Over the past two years, we’ve learned a lot about how language models can be used and abused—insights we couldn’t have gained without the experience of real-world deployment. In June 2020, we began giving access to developers and researchers to the OpenAI API, an interface for accessing and building applications on top of new AI models developed by OpenAI. Deploying GPT-3, Codex, and other models in a way that reduces risks of harm has posed various technical and policy challenges.
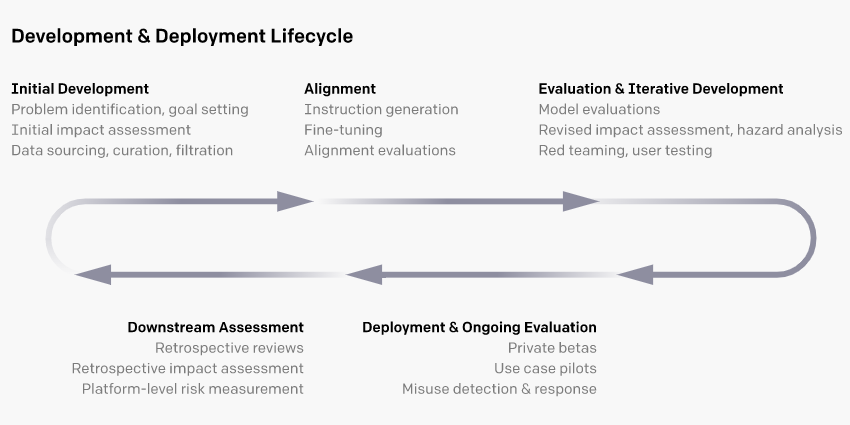
Overview of Our Model Deployment Approach
Large language models are now capable of performing a very wide range of tasks, often out of the box. Their risk profiles, potential applications, and wider effects on society remain poorly understood. As a result, our deployment approach emphasizes continuous iteration, and makes use of the following strategies aimed at maximizing the benefits of deployment while reducing associated risks:
- Pre-deployment risk analysis, leveraging a growing set of safety evaluations and red teaming tools (e.g., we checked our InstructGPT for any safety degradations using the evaluations discussed below)
- Starting with a small user base (e.g., both GPT-3 and our InstructGPT series began as private betas)
- Studying the results of pilots of novel use cases (e.g., exploring the conditions under which we could safely enable longform content generation, working with a small number of customers)
- Implementing processes that help keep a pulse on usage (e.g., review of use cases, token quotas, and rate limits)
- Conducting detailed retrospective reviews (e.g., of safety incidents and major deployments)
There is no silver bullet for responsible deployment, so we try to learn about and address our models’ limitations, and potential avenues for misuse, at every stage of development and deployment. This approach allows us to learn as much as we can about safety and policy issues at small scale and incorporate those insights prior to launching larger-scale deployments.